Modern AI is exceptional at generating JPA entity mappings. You describe your data model, say "We have leads with merchant details, rates, fees, and legal information", and within seconds you have a set of fully annotated entity classes with all the relationships wired up. Foreign keys are in place, cascades are configured, the schema compiles, and the API endpoints work.
What the AI has generated usually falls into one of two traps.
The first trap is flattening: everything gets crammed into a single table with dozens of columns, losing the structure that makes the data understandable.
The second trap is over-normalization: every related concept becomes its own table with its own repository, creating a complex web of join queries and transaction boundaries that make updates fragile.
The right answer usually lives between these extremes, but recognizing which extreme you are in requires architectural judgment about ownership semantics and update boundaries. That judgment is invisible to code generation tools.
The uncomfortable truth is that modern development practices have trained us to think of database schema as something that falls out of code generation. You model entities in your ORM, the framework creates tables, you move on. But the schema is not a consequence of your entity model. The schema is an architectural decision about how data relates and who owns what. Get that decision wrong, and your system becomes either a nightmare to query or impossible to update consistently.
The Problem: AI Generates Schema, Not Architecture
When you ask an AI to create an entity model, it uses sensible heuristics. It looks for one-to-many relationships and creates separate tables. It detects many-to-many relationships and creates join tables. It follows standard normalization rules. The output is a correct relational schema in the sense that it is normalized and internally consistent.
But it has no idea whether this schema matches how the data actually gets created, updated, and queried in your application. It does not know whether a "rates" table is something that stands alone with its own lifecycle, or whether it is always created and updated as part of a lead entity. It does not know whether you will query for a single rate in isolation, or whether you always fetch all rates together with the lead that owns them.
Related Articles
Shared topics and tags
Newsletter
Expert notes in your inbox
Subscribe for new articles.
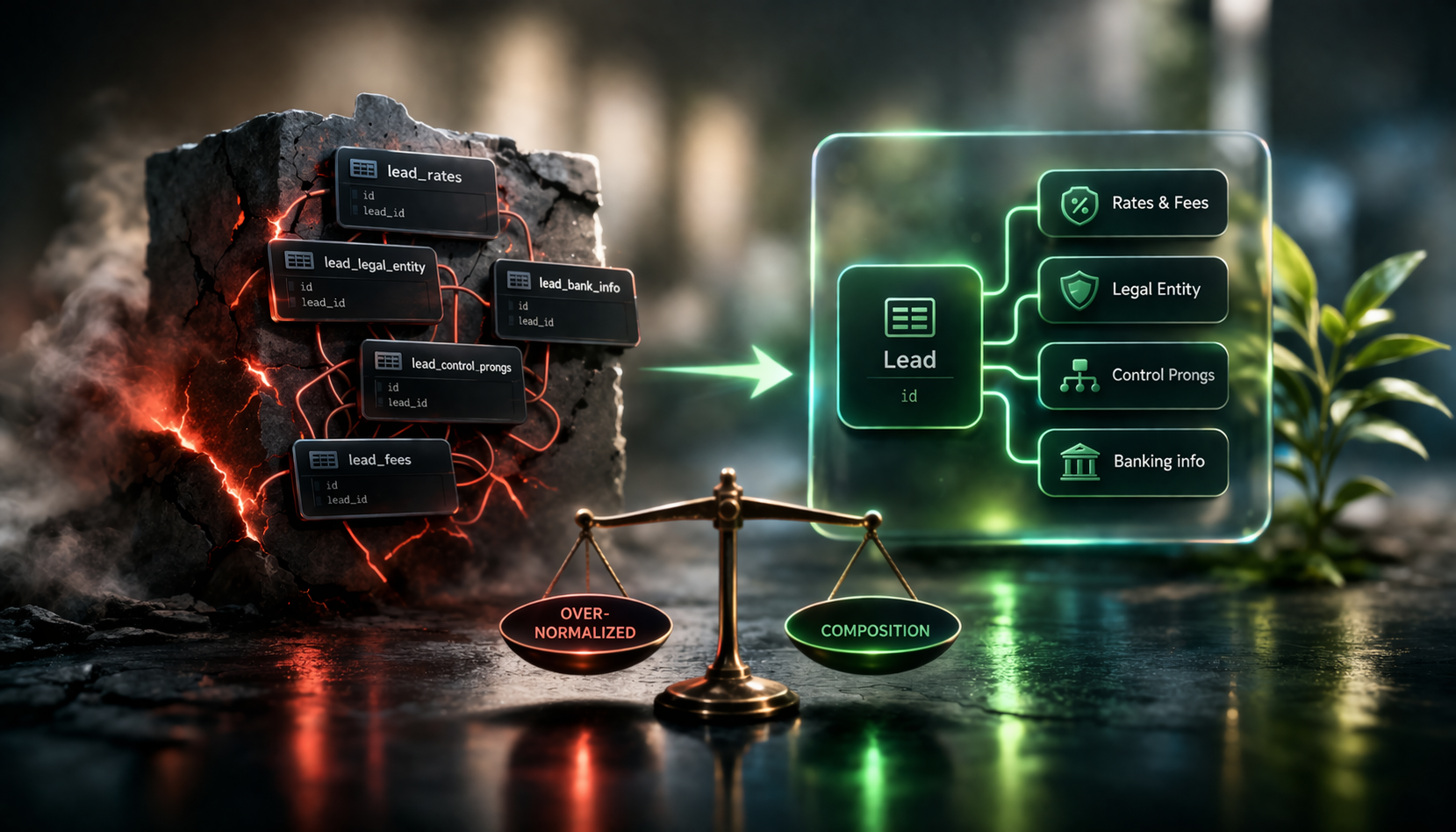
Consider a real-world example: a fintech application syncing lead information from an external CRM. The external system sends back a lead with sections: general information, rates and fees, legal entity details, control prongs, and banking information. Each section is a distinct part of the payload. Each section is updated independently by different CRM workflows.
The naive AI approach creates a separate table for each section. lead, lead_rates_and_fees, lead_legal_entity, lead_control_prongs, lead_banking_info. This feels correct because it mirrors the external structure.
But now you have a problem. When you update a lead, you need to update multiple tables. When the update to lead_rates_and_fees fails but the lead_legal_entity update succeeded, you have inconsistent state. Do you roll back the entire operation? Do you track which parts succeeded? The transaction boundary becomes unclear.
The overly-normalized approach creates another set of problems. Fetching a single lead now requires six queries or a complex join. Caching becomes difficult because cache invalidation has to span multiple tables. Pagination breaks because the lead counts are in one table but you filter on fields in another.
I have seen teams build systems where nearly every transaction involves updating five or six related tables. While the tests pass, and the code compiles, the operational troubleshooting becomes a nightmare because a single "lead update" is actually a distributed transaction spanning multiple tables with fuzzy consistency guarantees. They inherited this from schema design that prioritized normalization over update semantics.
The Pattern: Composition with Clear Ownership
The better approach starts with understanding ownership. When does a section get created? When does it get updated? By whom? Who owns the consistency guarantee?
In the lead example, the lead is the root entity. All the sections—rates, legal entity, control prongs are owned by the lead. They are always created when the lead is created. They are updated when the lead is updated, and same for deletion. This is composition, not association.
Composition means the child entity has no independent existence. It exists only as part of the parent. This is fundamentally different from a many-to-many relationship, where both entities have independent lifecycles.
When you model composition correctly, you have clear options. You can embed the child as part of the parent entity using @Embedded for value objects, or use @OneToMany with clear cascade semantics for entity collections. The key is that the child is always accessed through the parent. You never query RatesAndFees directly. You always fetch it as part of the Lead.
This decision has cascading architectural implications. If rates and fees are always fetched with the lead, you might decide to store them in the same row as a JSON column. If they are updated independently, you might use a separate table but with strict foreign key constraints and cascade delete. If they are queried independently by other parts of the system, you might reconsider whether they should be composed at all.
The point is that the decision should come first, then the schema follows. Not the other way around.
When AI Suggests "Just Add Another Table"
The problem with AI-generated schemas is that they default to maximum flexibility. Every relationship becomes a separate table and every potential query becomes a separate index. The resulting schema is normalized and theoretically flexible.
But flexibility has a cost. It costs in query complexity. A simple "fetch this lead" operation becomes a six-table join. It costs in update complexity, when a single "update the lead" operation cascades across multiple tables. It costs in caching strategy. Should you cache the lead alone or the lead with all its sections? If you cache it together, how do you handle stale section data? If you cache separately, you have cache coherency problems.
None of these costs are apparent when the schema is generated. They appear later, when the system is in production and you are trying to optimize query performance or handle concurrent updates safely.
A pattern I enforce consistently now: the first question about a new entity is not "what columns does it have?" It is "who owns this entity and when is it accessed?" If the answer is "it is always accessed as part of a parent entity," that tells you something about the schema. If the answer is "it can be accessed independently," that tells you something else. The schema should reflect that decision, not obscure it.
Composition Versus Association: The Ownership Question
The distinction between composition and association determines how you model the relationship. Composition means the child is owned by and accessed through the parent. Association means both entities exist independently and can be queried separately.
A lead with rates and fees is composition, because the rates and fees are conceptually part of the lead. They have no meaning outside the lead. They are accessed as part of the lead. The schema should reflect this: rates and fees could be a separate table with a foreign key to lead, or they could be JSON columns in the lead table, or they could be @Embedded value objects. The specific choice depends on query patterns and update frequency. But the ownership is clear.
A lead with a merchant is association. The merchant is an independent entity that might be associated with multiple leads. The merchant can be queried independently. The merchant has its own lifecycle. The schema should have a foreign key from lead to merchant, and you should be able to query merchants independently.
AI cannot distinguish between these because AI does not have the domain knowledge. You have to tell it. And most of the time, you have to tell it by making the decision explicit before you ask for code generation.
The schema question is fundamentally a domain question. Is this related data composed with the parent, or is it an association to an independent entity? That question comes from understanding how the data is created, updated, and queried. That understanding lives in the engineer, not in the AI.
The Cost of Schema Decisions
The reason schema decisions matter so much is that they are expensive to change. You can refactor code, you can rewrite a service. Changing the database schema in production is a multi-step, high-risk operation. You have to manage migrations, handle rollbacks, and also coordinate downtime or implement rolling deployments with dual-write logic. The cost of getting the schema wrong is measured in operational risk and downtime, not just in code complexity.
This is why the schema decision should come before you ask an AI to generate code. You need to understand: what is the unit of consistency? What is the unit of access? What are the transaction boundaries? Once you answer those questions, the schema mostly follows. If you skip those questions and let the AI generate a normalized schema, you will discover the answers through painful operational experience later.
Decision Framework and Why It Matters
Define ownership first: is this composed with the parent or independent?: Determines whether child entities have their own tables or are embedded
Understand the access pattern: is this always fetched with the parent or independently?: Shapes join strategy, caching strategy, and query optimization
Use cascade semantics that match ownership: Ensures deletion logic is correct and data consistency is maintained
Design the schema to match the domain model, not the other way around: Reduces friction in queries and updates; makes the system easier to reason about
Ask "what owns this?" before asking "what table should this be?": Prevents over-normalization that optimizes for theoretical flexibility instead of actual usage
Final Thoughts
The shift in how engineers work in an AI-augmented world shows up nowhere more clearly than in data modeling. The old flow was: write entities, generate schema, build queries. The new flow needs to be: understand ownership, decide composition versus association, then ask AI to generate entities that reflect those decisions.
This requires architectural thinking that happens before you write a line of code. It is the kind of thinking that cannot be automated. AI can take a clear decision about entity composition and generate correct JPA mappings all day. But AI cannot decide whether your rates and fees are conceptually part of your lead or independent entities that happen to be related to it.
That decision is architecture. That decision is what separates a system that scales gracefully from one that becomes a nightmare to maintain. And that decision is exactly what modern engineers need to focus on as the cost of implementation drops and the value of judgment rises.
*Share this with your team before they ask an AI to generate the entity model for the next service. The question to ask before code generation is not "what schema should this be?" but "who owns this data and when is it accessed?" The schema should follow from that understanding, not precede it.